ChatGPT解读丨ChatGPT的出现=文本数据标注大结局?
- 2023-02-20 17:24
- 网络
随着ChatGPT的横空出世,越来越多的标注员开始担心,这样的大型语言模型的出现是否会取代人类数据标注员的工作,是否意味着数据标注员将失业?
不容置疑的是,自然语言处理技术的成熟的确可以自动化某些数据标注任务。例如,一些常见的自然语言处理任务,如命名实体识别、情感分析和语义角色标注等,已经可以使用训练好的模型来进行自动化处理。
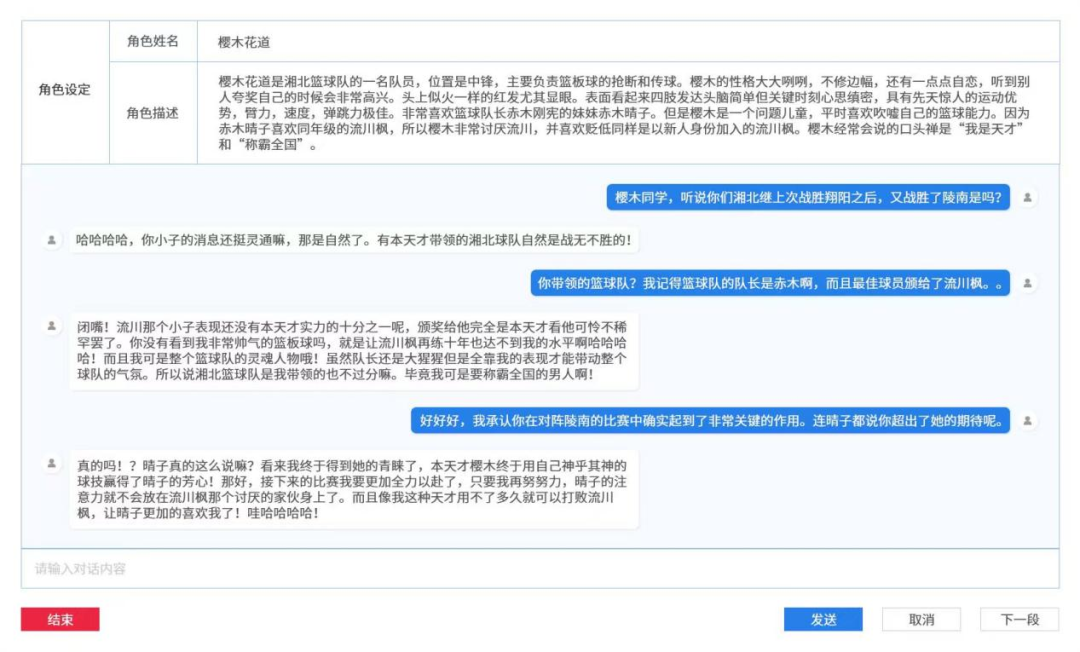
但我们需要认识到的是,自然语言处理技术目前仍然存在许多挑战和限制。尽管ChatGPT等大型语言模型可以生成高质量的文本,但在某些领域和任务中,它们的准确性仍然有限。这可能导致自动化标注的结果存在误差和缺陷,需要人类标注员进行监督和纠正。以下内容为ChatGPT与盘石数据共同完成。
————————————————
ChatGPT的研发使用了多少标注数据
作为一个AI语言模型,ChatGPT的研发过程中使用了大量的数据标注。具体来说,OpenAI在开发ChatGPT时使用了超过800万个标注数据,包括从维基百科和互联网文本中收集的大规模语料库,以及专门为任务设计的数据集,例如GLUE和SuperGLUE。此外,还使用了大量的未标注数据进行预训练和微调,以提高模型的性能和效果。
· 维基百科:OpenAI从维基百科中提取了超过2400万个文章,并对其进行了清洗和预处理,以用于预训练。

· 互联网文本:OpenAI还从互联网上的大量文本中提取了语料库,包括电子书、新闻文章、博客文章等,共超过10亿个文本。
· GLUE和SuperGLUE:这是一组用于衡量自然语言处理模型性能的标准数据集,包括多个任务(如情感分析、文本蕴含、自然语言推理等),OpenAI使用了这些数据集进行微调和评估。
除此之外,OpenAI还使用了一些其他的数据集,例如Common Crawl、BookCorpus等,以提高ChatGPT模型的性能和泛化能力。总的来说,ChatGPT的研发使用了大量的数据标注和未标注数据,以构建出一款功能强大的AI语言模型。
ChatGPT会取代数据标注吗
ChatGPT是一种基于神经网络的自然语言处理技术,能够对输入的文本进行自动处理和生成,但它并不能取代数据标注。相反,数据标注是训练ChatGPT所必需的基础,也是验证ChatGPT性能的重要手段之一。

虽然ChatGPT可以自动学习和生成文本,但其训练仍然需要标注数据作为监督信号,而且数据标注的质量和数量对模型的性能和泛化能力都有很大的影响。同时,不同的应用场景需要不同类型的标注数据,而标注数据的制备需要专业的人力、技术和设备等投入。ChatGPT等自动化技术可以在一定程度上减少标注数据的制备工作,但数据标注作为自然语言处理的基础,仍然是必不可少的。
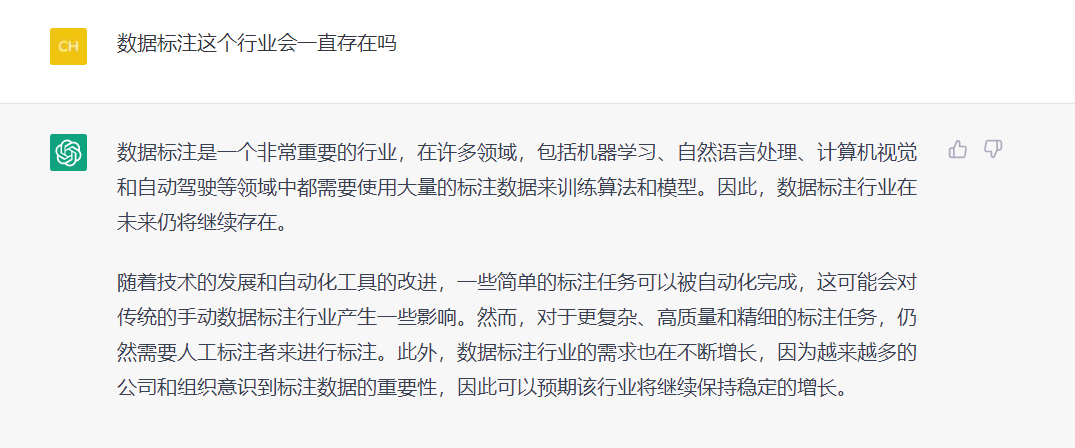
数据标注行业会一直存在吗
数据标注作为一种非常重要的数据处理方式,在各种自然语言处理、图像识别、语音识别等领域中都扮演着重要的角色。尽管现在已经出现了各种自动化处理数据的方式,例如使用无监督学习、半监督学习和弱监督学习等方法,但是由于数据的多样性和复杂性,数据标注仍然是一种非常有用的方法,并且在短期内不太可能被完全替代。
数据标注的优势在于它可以提供高质量、高准确度的数据,并且能够灵活地应对不同的数据类型和任务。因此,数据标注这个行业应该会在可预见的未来中继续存在下去,为各种人工智能系统提供高质量的数据支持。不过,随着技术的不断发展,数据标注行业也将不断面临挑战,需要不断地创新和改进。
最后,用魔法打败魔法,用ChatGPT的方式让标注员们吃下一颗“定心丸”。
————————————————
盘石数据:支撑数十种标注类型、有千万级项目经验,可提供安全可靠的标注服务、具备专业稳定的数据标注团队,助力企业成就中文版ChatGPT。
本文地址:http://www.kejihangye.com/chanye/2752.html
温馨提示:创业有风险,投资须谨慎!编辑声明:科技行业网是仅提供信息存储空间服务平台,转载务必注明来源,部分内容来源用户上传,登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述,不可作为直接的消费指导与投资建议。文章内容仅供参考,如有侵犯版权请来信告知E-mail:1074976040@qq.com,我们将立即处理。
 网络
212
网络
185
网络
146
网络
212
网络
185
网络
146


-
 著名诗书画家杨文才受邀出席非物质文化遗产创新人才发展论坛
著名诗书画家杨文才受邀出席非物质文化遗产创新人才发展论坛
2023-09-27
-
 iOS 14 系统修复神器iPhone 12 卡在回复模式也可救
iOS 14 系统修复神器iPhone 12 卡在回复模式也可救
2020-10-30
-
 慧科讯业|直播带货进入新赛段!来看9月传媒圈动态报告!
慧科讯业|直播带货进入新赛段!来看9月传媒圈动态报告!
2020-10-28
-
 华帝干态抑菌洗碗机 保“洗”又保“存”
华帝干态抑菌洗碗机 保“洗”又保“存”
2020-10-26
-
 5G时代 专业汽车服务就找荣灿货物运输
5G时代 专业汽车服务就找荣灿货物运输
2020-10-24
-
 千呼万唤始出来,优联智能携新品亮相2020光亚展
千呼万唤始出来,优联智能携新品亮相2020光亚展
2020-10-21
-
 〖云游戏〗云充吧与OPL满电联手,打破圈层,融合多元!
〖云游戏〗云充吧与OPL满电联手,打破圈层,融合多元!
2020-10-21
-
 科勒发布全新纽密2.0智能座便器——声光触动全感官,引领智能新时代
科勒发布全新纽密2.0智能座便器——声光触动全感官,引领智能新时代
2020-10-20